
Building Smart Data Pipeline with Firestore, LangChain, and BigQuery
I recently had to build a data pipeline for my website, Sphinx Mind, where I aimed to achieve two objectives:
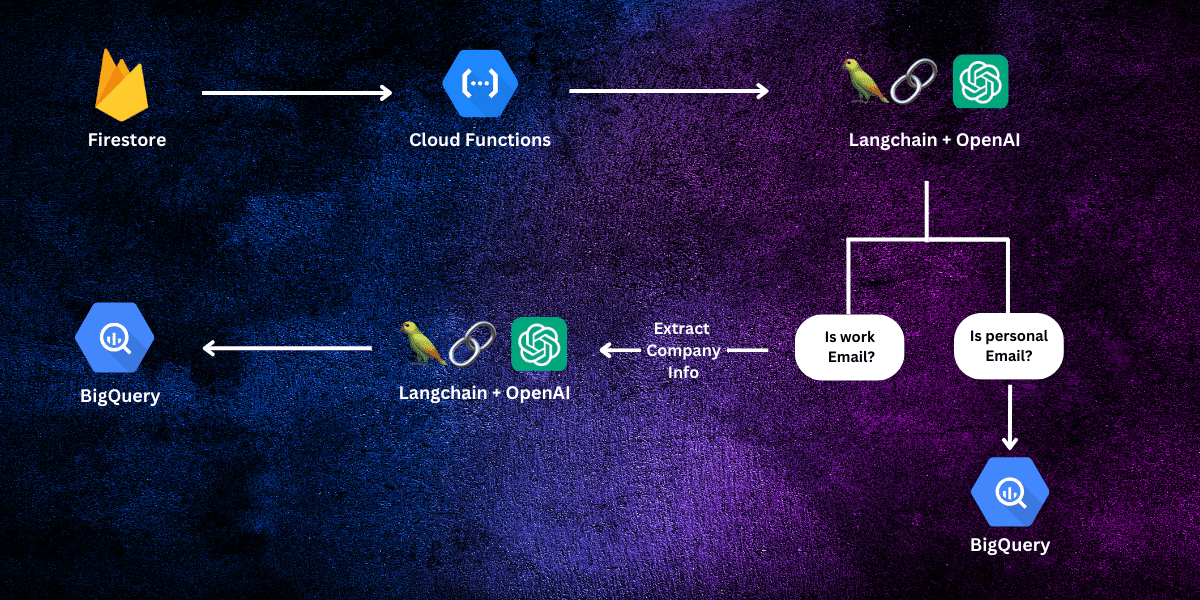
- Transfer user data from Firestore to BigQuery for analytics purposes.
- For each user with a work email, I wanted to retrieve their company information, such as the company name, address, etc., since this info isn’t requested during sign-up.
The task of moving data from Firestore to BigQuery is straightforward. We can either use Firebase Functions or extensions. In this case, I went ahead with functions as I wanted to perform data transformation before uploading data to BigQuery.
The transformations I wanted to do are the following:
- Identify if the user’s email is personal or work-related.
- If the email type is work, we extract the company domain from the email.
- We crawl this domain and scrape the homepage content.
- We use this content to extract information like company name, address, description, industry, etc.
This can somehow be achieved through traditional coding methods. However, since we are fortunate to live in the era of Generative AI, I will be using Langchain + GPT-4 to do all this heavy work for us.
If you aren’t familiar with Langchain, it’s a framework for building chains and agents, it simplifies the creation of applications using large language models.
The first step in our data pipeline is to build a Cloud Function that gets triggered when a new document is added to my “users” Firestore collection. This user doc should have the user email, we will use to build our chains.
I won’t cover the part about how to retrieve data from Firestore here. Instead, I’ll focus more on building the chains and obtaining company information.
Here is our chains workflow:
- Build a chain to classify user emails as either
“work”or“personal”. - If the email is
“personal”, we simply store it in BigQuery without any additional steps. - If the email is
“work”, we proceed to the next step, which involves extracting the domain. - Build a BeautifulSoup crawler to get all the text only from the website.
- Create a second chain to process this content and return a JSON object with the necessary company information.
1- Email type chain
First, make sure to install Langchain if you haven’t already:
pip install langchain
The first step in building a chain is to write a prompt. Our prompt will be very short and straightforward. It will take one input, which is {email}, and should return either "work" or "personal."
The second step is to choose the AI model to use. In our case, we’ll use GPT-4 turbo. You can use any model you wish, just make sure to add your OpenAI key.
Lastly, we add our parser, which is simply a string formatter.
Here’s the function to classify an email:
def classify_email(email):
prompt = ChatPromptTemplate.from_template(
"Is this email: {email} work or personal? Don't narrate, just answer with either 'work' or 'personal', nothing more.")
model = ChatOpenAI(
model="gpt-4-1106-preview",
openai_api_key=openai_api_key)
chain = prompt | model | StrOutputParser()
return chain.invoke({"email": email})
The | symbol acts like a Unix pipe operator, chaining together the different components and feeding the output from one component as input into the next component.
2- Build the crawler
Our first chain should return “work” or “personal”. We will only proceed with this step if the email type is "work".
First, we will write two simple lines of code to get the domain from the email and then append it to 'https://'.
domain = email.split("@")[1]
url = "https://" + domain
Now, it’s time to build the crawler. We will use the requests and BeautifulSoup libraries. Make sure to install these two libraries first if you haven’t:
pip install requests
pip install beautifulsoup4
The code is quite simple. We will set our user agent to avoid getting blocked by websites, and then we will return only text, excluding HTML, CSS, JavaScript, etc.
Here’s the function to get all text content from a URL:
def get_text_from_url(url):
headers = {
'referer': 'https://www.google.com/',
"User-Agent": 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.50 Safari/537.36'
}
try:
response = requests.get(url,
headers=headers,
timeout=10,
verify=False,
allow_redirects=True)
# Check if the request was successful
if response.status_code in [200, 201]:
# Parse the content of the page using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract and return the text
return soup.get_text(separator='\n', strip=True)
else:
raise Exception(
"Error: Unable to fetch the page, status code: " + str(response.status_code))
except Exception as e:
raise e
This function sends a request to the specified URL and, if successful, extracts and returns the text content of the page.
3- Company Info Chain
Now that we have the website content, it’s time to feed it to the AI model for categorization and information extraction.
The first thing we do is create our prompt. The prompt is also simple. We instruct the model to extract information like the company’s name, description, location, and industry. You can ask for more details as you wish.
The output format of this should be JSON. Note that we passed response_format equal to json_object. We also emphasized this in our prompt by asking the model to return only a JSON object.
Here’s the function to get company information from website content:
def get_company_info_from_website_content(website_content):
json_model = ChatOpenAI(
model="gpt-4-1106-preview",
model_kwargs={"response_format": {"type": "json_object"}},
openai_api_key=openai_api_key)
prompt = ChatPromptTemplate.from_template('''
Given this website content below, return a JSON object with the following keys:
- name: the name of the company.
- description: summarize a short description about the company in 1-2 sentences max.
- location: the location of the company, return N/A if not found.
- industry: the industry of the company, for example: 'Digital Marketing', 'Software', 'Financial Services'.
Don't narrate, just answer with a JSON object, nothing else.
Website content:
{website_content}
''')
chain = prompt | json_model | StrOutputParser()
res = chain.invoke({"website_content": website_content})
# convert res from json to a python dict
try:
res = eval(res)
except:
print(f"Error: Unable to parse json, here's the response: {res}")
return
return res
4- Putting It All Together
Now, let’s run a test to see how the entire process works by providing my email as a test case. This will demonstrate how the chains and functions we’ve built interact with each other to achieve the desired outcome.
- Email Classification: First, the
classify_emailfunction will determine whether the email is for ‘work’ or ‘personal’ use. - Domain Extraction and Web Crawling: If it’s a ‘work’ email, the domain is extracted and passed to the
get_text_from_url functionto crawl the website and retrieve text content. - Company Information Extraction: The retrieved website content is then fed into the
get_company_info_from_website_contentfunction, which uses our AI model to parse the content and extract company information in JSON format.
Let’s see what happens when I input my email:

Bingo! It worked. The model successfully extracted information about my company. We can now stream this data directly to my BigQuery table. I won’t cover this part in this post as I have already discussed it in many of my articles on this blog. However, if you have any questions, feel free to let me know.
Below is the full code that brings all these steps together:
from bs4 import BeautifulSoup
import requests
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
import os
openai_api_key = os.environ.get("OPENAI_API_KEY")
def get_company_info_from_email(email):
email_type = classify_email(email).lower()
if email_type not in ["work", "personal"]:
print(f"Error: Invalid email type, got {email_type}, exiting...")
return
if email_type == "personal":
print(f"This is a personal email, exiting...")
return
elif email_type == "work":
print(f"This is a work email, continuing...")
# extract domain from email
domain = email.split("@")[1]
url = "https://" + domain
try:
website_content = get_text_from_url(url)
except Exception as e:
print(e)
return
# extract company info from website content
company_info = get_company_info_from_website_content(website_content)
return company_info
def classify_email(email):
prompt = ChatPromptTemplate.from_template(
"Is this email: {email} work or personal? Don't narrate, just answer with either 'work' or 'personal', nothing more.")
model = ChatOpenAI(
model="gpt-4-1106-preview",
openai_api_key=openai_api_key)
chain = prompt | model | StrOutputParser()
return chain.invoke({"email": email})
def get_text_from_url(url):
headers = {
'referer': 'https://www.google.com/',
"User-Agent": 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.50 Safari/537.36'
}
try:
response = requests.get(url,
headers=headers,
timeout=10,
verify=False,
allow_redirects=True)
# Check if the request was successful
if response.status_code in [200, 201]:
# Parse the content of the page using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract and return the text
return soup.get_text(separator='\n', strip=True)
else:
raise Exception(
"Error: Unable to fetch the page, status code: " + str(response.status_code))
except Exception as e:
raise e
def get_company_info_from_website_content(website_content):
json_model = ChatOpenAI(
model="gpt-4-1106-preview",
model_kwargs={"response_format": {"type": "json_object"}},
openai_api_key=openai_api_key)
prompt = ChatPromptTemplate.from_template('''
Given this website content below, return a JSON object with the following keys:
- name: the name of the company.
- description: summarize a short description about the company in 1-2 sentences max.
- location: the location of the company, return N/A if not found.
- industry: the industry of the company, for example: 'Digital Marketing', 'Software', 'Financial Services'.
Don't narrate, just answer with a JSON object, nothing else.
Website content:
{website_content}
''')
chain = prompt | json_model | StrOutputParser()
res = chain.invoke({"website_content": website_content})
# convert res from json to a python dict
try:
res = eval(res)
except:
print(f"Error: Unable to parse json, here's the response: {res}")
return
return res
Entrepreneur focused on building MarTech products that bridge the gap between marketing and technology. Check out my latest products Markifact, Marketing Auditor & GA4 Auditor – discover all my products here.